Over the past several months, we’ve been exploring a new approach to rapid internal prototyping using Databricks Apps to build, test, and refine AI-driven concepts directly on top of live data. This wasn’t a production build. It was deliberate R&D, a safe environment to experiment, learn fast, and figure out what’s worth scaling. The results reinforced a simple but powerful idea: when you bring application development closer to the data itself, innovation accelerates.
Rapid Prototyping, Right on the Platform
We started inside Databricks Notebooks, writing small Python-based “agents” designed to analyze, mine, or enrich data from different sources. From there, we used Databricks Apps, built with Streamlit, to give those agents lightweight interfaces and Databricks Asset Bundles to package, version, and deploy everything seamlessly.
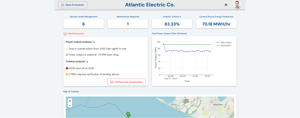
The entire workflow stayed inside Databricks, with no extra cloud hosting, no new servers, and no additional pipelines. The key here is getting away from managing infrastructure, which can take a lot of time and effort by other team members, allowing the focus to stay on experimentation and results. That proximity to the data changed everything. When your apps run directly on the same platform where the data already resides, latency disappears, hand-offs go away, and the feedback loop gets much tighter.
Innovation isn’t born from perfection; it’s born from proximity, iteration, and the freedom to explore.
We also extended our setup to use Jupyter notebooks for local development, letting our engineers iterate and debug code on their own machines before pushing updates back through a shared repository. That hybrid model, combining local speed with cloud governance, kept us nimble and consistent at the same time.
Databricks: A Platform Built for Builders
One of the strengths of Databricks Apps is how flexible it is in supporting multiple UI frameworks. You’re not locked into a single way of building; there’s a spectrum depending on what kind of prototype you’re trying to create.
Frameworks Supported by Databricks Apps
| Framework | Primary Language | Typical Use Case | Key Advantage |
|---|---|---|---|
| Streamlit | Python | Fast data apps and internal dashboards | Extremely simple for data scientists; minimal setup. |
| Dash | Python | Analytical dashboards with rich Plotly charts | Great for interactive visualizations and reporting. |
| Gradio | Python | Machine learning model demos / AI interfaces | Perfect for quick ML model testing with input/output UIs. |
| Flask | Python | Lightweight web apps and REST APIs | Gives developers full control when needed. |
| Shiny | R / Python | Statistical dashboards and analytical visualizations | Familiar to analytics teams and R-heavy users. |
| Node.js | JavaScript / TypeScript | Custom web apps or interactive front ends | Ideal for larger or highly customized use cases. |
Why Python Everywhere Matters
For data developers, the magic here is that Python spans both worlds: data engineering and application development. Its interpreted nature enables fast prototyping and iteration, while its vast ecosystem of ready-to-use libraries accelerates experimentation and integration. That alignment means data scientists and engineers can build full prototypes without switching languages or teams.
The same Python skills used to prepare data or train a model now extend to creating interactive, data-driven interfaces. It breaks down the barriers that used to slow innovation, and for internal R&D, where iteration speed matters more than polish, that’s a major advantage.
Streamlit: Speed Over Ceremony
In our case, Streamlit was the right fit. We could stand up working UIs with just a few lines of code, adding sidebars, graphs, and inputs in minutes instead of days. Streamlit abstracts away the front-end complexity, letting you focus on logic and data. For data scientists and AI engineers, that accessibility is gold. It turned experimentation into a conversation: try something, test it, share it, repeat.
Asset Bundles: The Glue That Holds It Together
Databricks Asset Bundles (DABs) gave structure to the creative process. Instead of scattered notebooks and ad hoc scripts, we could define entire applications, dependencies, configurations, and resources in a single, versioned package. That brought the kind of discipline and traceability you’d expect in production DevOps into an R&D workflow: version control with Git integration, environment promotion (dev to test to staging), and reproducibility across users and machines.
And with Jupyter in the mix for local testing, every developer could build confidently, knowing their work would run the same in the shared Databricks workspace. It felt like we had finally bridged the gap between data notebooks and real software engineering.
Built-In AI Experimentation Tools
Another strength of Databricks is how much visibility it gives you while you experiment. All of the AI experimentation tools, from job tracking and lineage tracing to model performance monitoring, come built in. We could trace queries and see exactly where results came from, debug issues in real time using centralized logs, gauge confidence in results through experiment tracking, and understand performance trends and errors across runs.

Having all of that instrumentation inside the same workspace meant no disconnected dashboards, no manual tracking, and no guesswork. MLflow’s APIs and format make it portable, so you’re never locked into a single vendor’s ecosystem. It’s everything you need to build, test, and learn in one governed, observable environment.
Multi-Tenancy Isolation and Authentication
One area we explored was multi-tenant authentication and data isolation, a common challenge in shared environments. During this exploration, we also discovered that ‘On Behalf Of’ (OBO) authentication is currently supported for the Databricks SQL connector but not for PySpark. Because many of our use cases rely heavily on PySpark, we chose to have the app run under the Service Principal (SP) of the application and provide user-based access directly within the app. This approach preserved flexibility while maintaining security and access control. It worked for experimentation, but it’s not something we’d put in production yet. That’s a future article and likely a future Databricks capability as the platform matures.
The Business Perspective, Speed and Proximity
From a business standpoint, this experience showed just how valuable speed and proximity can be. When data, logic, and application all live in the same place, you get from idea to working prototype in hours, not weeks. You can test hypotheses on live data instead of samples. You can validate ideas faster, cheaper, and with clearer feedback. Even though Databricks Apps aren’t meant for external SaaS products today, they’ve opened the door to a new way of working, one where R&D feels faster, cleaner, and more aligned with real-world data. For business leaders, this means better ROI on experimentation and earlier visibility into what’s actually working.
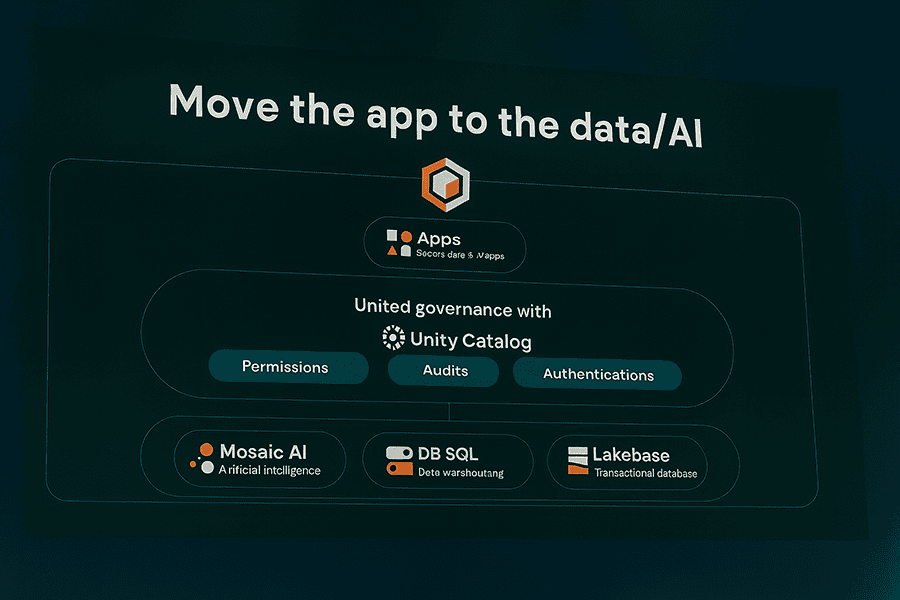
Databricks as an Innovation Platform
What excites me most is how these capabilities turn Databricks into a true innovation platform. It’s no longer just about analytics or pipelines; it’s about building, testing, and refining ideas in real time without leaving the governed data environment. That convergence of data, code, and application reduces friction, increases iteration speed, and brings R&D closer to production readiness without pretending it’s already there. The lesson is clear: innovation doesn’t need to wait for the perfect system; it needs an environment where curiosity can move fast and stay grounded in data. That’s exactly what Databricks Apps and Asset Bundles delivered.
Reflections and Looking Ahead
Exploring New Directions
We’re continuing to explore new directions, especially around multi-tenant design and embedded dashboards, where Databricks is already expanding. It’s not hard to imagine a future where today’s internal R&D apps evolve into fully governed, customer-facing tools. But for now, the sweet spot is right here: rapid internal prototyping, close to the data, in a single platform built for speed, governance, and experimentation. When the distance between idea, data, and insight disappears, that’s when real innovation starts to move.
Why R&D Matters
Every once in a while, you find a toolset that reminds you why R&D matters. This experience did that for me. It wasn’t about scale or polish; it was about possibility. About shortening the path between curiosity and clarity. And about rediscovering that innovation isn’t born from perfection; it’s born from proximity, iteration, and the freedom to explore. That’s where Databricks really shines.
Authors: Mark Stratton [LI] · Shawn Davison [LI] & Amit Agrawal [LI]
