
The data analytics buzzwords are quickly changing these days and rapid transformation is occurring in the data space—pun intended. There are multiple data workload transformation patterns that have emerged, and it’s not obvious what the differences are or how they are being used from a practical perspective. We’ve gone from traditional data warehouses and big data marts to Cloud-based data lakes and more recently the lakehouse and data mesh.
So, what is driving this transformation?
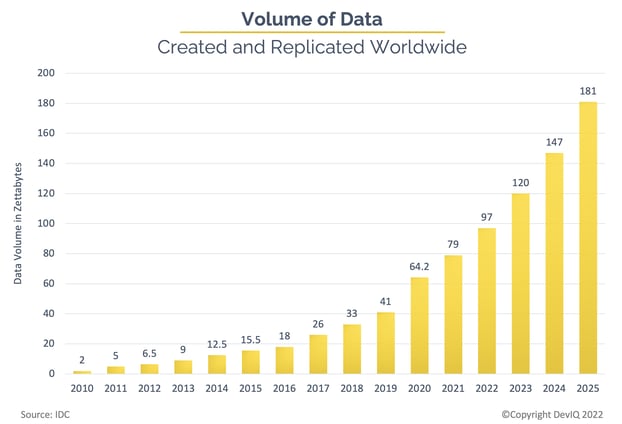
Luckily, it’s not just toothpaste marketing that is moving this trend. New data is being generated today at an unprecedented rate. Internet of things (IoT) is generating more data every day than most of us can imagine—due to the increasing number of connected sensors and devices being deployed. According to IDC, IoT ALONE will be generating almost 80 ZB (zettabytes) by 2025, from more than 64 billion sensors and devices. One zettabyte is one billion terabytes (TB) or one trillion gigabytes (GB).
History: Data Warehouses and Big Data Marts
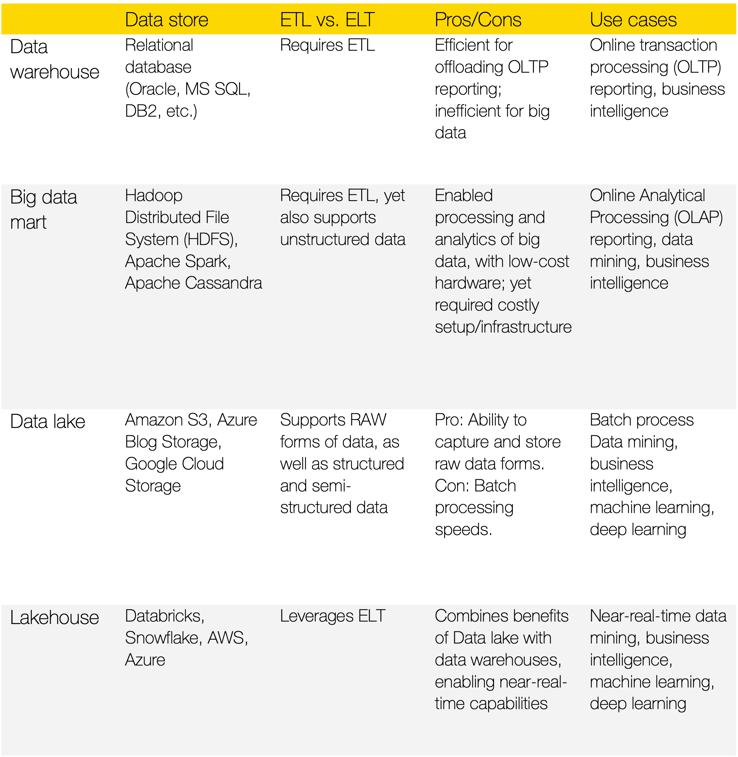
Data warehouses have been around for a long time (see history here). The traditional data warehouse is a very structured repository required specialize skills and significant pre-thought to create schemas. Star schemas and snowflake schemas (more complex star schemas) are the most common data warehouse structures. The primary value prop is that they denormalized the data in ways that increase performance of reporting and analysis. However, more often than not, a data warehouse is usually a copy of the data that is used in the operational (OLTP) system.
Big data marts have enabled data warehouses to scale by segregating large amounts of data and analysis on a specific business line or group of users. Apache Hadoop and Apache Spark open-source frameworks came out of the development and evolution of Big Data clusters, with advent of the Hadoop File System (HDFS) and later the Spark in-memory Resilient Data Dataset (RDD), which increased performance 100X, using low-cost hardware.
This was in the pre-Cloud computing era, and the Data world has changed dramatically since. That said, Cloud adoption has just past the tipping point recently, and there are swarms of companies still using pre-Cloud data warehousing legacy technologies.
Some of the most popular Public Cloud data warehouses (e.g. AWS Redshift, Google Cloud DataProc, Azure Databricks) are commercialized versions of Hadoop and Spark.
Data Lakes
The cloud-based data lake was the next big step in the evolution of the data transformation space. It abandoned the centralized schema structures of the data warehouse and the big data mart. It allowed data to be stored in its raw/captured form. It brought the ability to store and manage structured as well as semi-structured and unstructured data, using low-cost cloud file storage, such as Amazon S3 (simple storage service), Azure Blog Storage or Google Cloud Storage. The reduced cost and unlimited storage has made it possible to store and process much larger volumes of data.
Today, data lakes for the most part are repositories of raw data that can be accessed on-demand. Part of the value prop is that data lake data can be re-processed if needed to create additional value, or intentionally retained for future use. Storage groups, often referenced by “Hot”, “Warm” and “Cold” temperature, define how frequent data is accessed and what the delay is in retrieving the data.
Data lakes are extremely proficient at handling streaming data that is being ingested in real-time. Because data lakes mostly consist of raw unprocessed data, a data scientist with specialized expertise is typically needed to manipulate and translate the data. One of the main use cases for a data lake is to leverage it for batch processing, while also enabling self-service “transformation” for data ingestion, processing, and scheduling to automate the complexity of building and maintaining data pipelines.
ETL vs. ELT
The data lake is based on the principle of Extract, Load and Transform (ELT). ELT can be a more efficient and scalable approach to data loading than the legacy Extract, Transform and Load (ETL) approach. With ELT, the data is loaded into the data store in its raw form. The data is then transformed into the desired format in the data store based on analytics, reporting and application needs. Transformations are the hard part, that change based on changing business and technical requirements. By separating the transformation step from the extract and load steps, this allows for greater flexibility in transforming the data where and when it is required instead of “guessing” how the data will be used.
With ETL, the data is first transformed into the desired format and then loaded into the data store. This approach requires the data team to know all the requirements for how the data needs to be transformed up front and creates a much more rigid process. When business and technical requirements change, the data team will have to update the ETL process to accommodate those changes. History has shown that complex and rigid ETL processes have greatly impacted the effectiveness of traditional Data Warehousing efforts and often are the cause of their demise.
Traditional ETL (Extract, Transform and Load) tools and processes are now being replaced with ELT (Extract, Load and Transform) technology. This enables data ingestion or loading and extraction to be done in an automated way, which means it’s accelerating the rate by which data can be moved and transformed—dramatically.
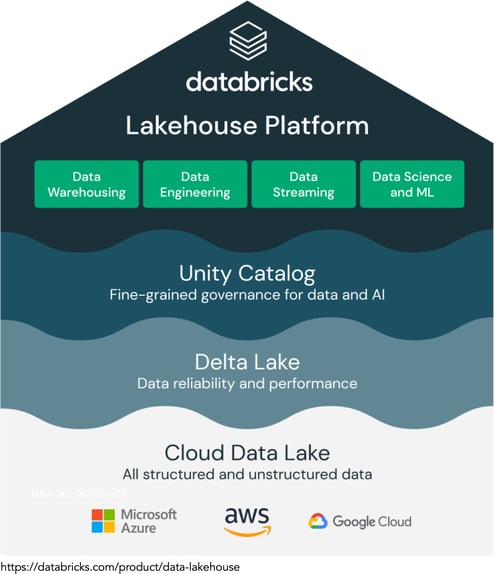
Data Lakehouse
A data lakehouse combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data. Data teams can move faster as they are able to use data without needing to access multiple systems. Data lakehouses also ensure that teams have the most complete and up-to-date data available for data science, machine learning, and business analytics projects.
Future: Data Mesh
Data Mesh is the latest buzzword and evolution in the transformation space. However, it’s too soon to know how successful data meshes will be, as it is very early in the evolution and the tooling is still maturing.
There are varying definitions of a data mesh, yet the common theme is that they are inherently distributed and enable faster access to real-time data. In practical terms, this may simply mean there is more than one data lake that is serving as a source, and there multiple lakehouses have been deployed to support multiple business units, not unlike data marts served this purpose in previous generations.
Another perspective is that data is accessible and can be processed on the “Edge”, as well as in a centralized Cloud data lake. IoT devices in a mesh can connect directly to each other, or they can connect through a central server or hub. Data meshes are expected to be used in industrial and commercial settings, where they can be used to manage and monitor machines and other equipment in real-time. The expectation is that they will replace legacy SCADA and PLC systems, with a new generation of real-time processing capability.
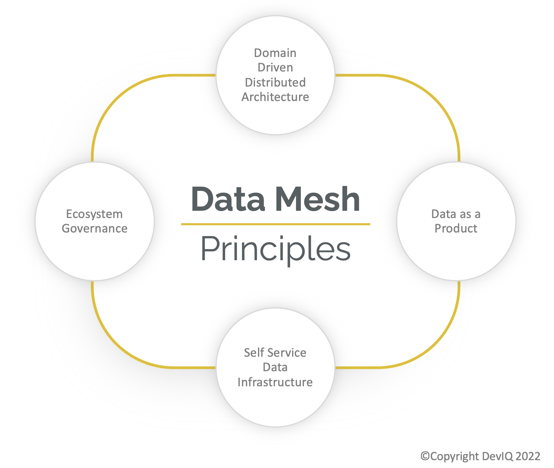
The evolutionary difference in a data mesh is the reality that data is very distributed today and that it is costly and a performance hit to centralize it. The real-time nature of Industrial IoT and other use cases make a case for supporting distributed data meshes. The reality is data meshes are more theory than reality today and there are no commercial or open-source solutions that have been defined as clear winners in this space…to-date.
The following is a brief comparison and evolution of the most popular Data Architectures in use today:
Conclusion
Data transformation architectures and tools are evolving faster than ever. Knowing which data architecture and tools to apply to a specific use case is becoming the challenge, as there are many options to choose from.
On the commercial front, Snowflake and Databricks are two of the most popular Data platforms for supporting many of these architectures. Amazon AWS, and Microsoft Azure also have services to enable these transformation patterns; however, each new generation is introducing new complexities that the previous generation did not have. In particular, the distributed nature of data meshes requires experience in all of the previous generations as well as development of modern pipelines, streaming and event processing technologies. In many cases, identifying the right solution today requires a solid understanding of both legacy and modern architectures.
The volume of data is increasing exponentially, as well as the complexity of managing and processing it. Architecting the right solution for the business use case is becoming more important than ever—to generate the business value desired.
Shawn Davison & Ryan Sappenfield
